Time Space Complexity of Basic K-means Algorithm The basic k-means clustering algorithm is a simple algorithm that separates the given data space into different clusters based on centroids calculation using some proximity function. OKnt dist K number of clusters centroids n number of objects Bound number of iterations I giving OIKnt dist for m-dimensional vectors.

Clustering On Database Systems Rkm
For example Write code in CC or any other language to find maximum between N numbers where N varies from 10 100 1000 10000.

K means time complexity. Clustering - What is Big-O time complexity of K-means - Mathematics Stack Exchange. Time complexity of a particular algorithm is a function this function takes input as length of data entered in that algorithm and determines how much time or cycles need to run that algorithm for that input. The standard algorithm only approximates a local optimum of the above function and so do all the k-means algorithms that Ive seen.
And compile that code. In this article an attempt is made to develop an. 2 Initialization To choose k starting points which are used as initial estimates of the cluster centroids.
In this answer note that i used in the k-means objective formula and i used in the analysis of the time complexity of k-means that is the number of iterations needed until convergence are different. The average complexity is given by Ok n T where n is the number of samples and T is the number of iteration. In Kmeans the spacecomplexity is O n M d and the time complexity is O M n I d.
6 Ikmn operations I k-1mn operations Ik m-1 1n operations. The worst case complexity is given by Onk2p with n n_samples p n_features. Algorithmic steps for K-Means clustering 12 1 Set K To choose a number of desired clusters K.
ONPKi where i is the iteration amount. This means if data is not dimensionally big K-Means can have Linear Complexity and if data gets very dimensional theoretically time complexity can go up to Quadratic. To make it more clear lets take an detailed example.
The k-means problem is solved using either Lloyds or Elkans algorithm. Time Complexity of K-means Let t dist be the time to calculate the distance between two objects Each iteration time complexity. This would be similar to what I found in this paper A Survey on Clustering Algorithms and Complexity Analysis for Kmeans.
This results in a partitioning of the data space into Voronoi cells. As it has been mentioned in the comment section I can be exponential in n if you run the algorithm to completion. Number of clusters I.
K-means clustering is a method of vector quantization originally from signal processing that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean serving as a prototype of the cluster. On K I d n. The k-means algorithm is known to have a time complexity of O n 2 where n is the input data size.
The k-means algorithm is known to have a time complexity of O n2 where n is the input data size. This quadratic complexity debars the algorithm from being effectively used in large applications. Which means you cant just cut down OnKID to be On.
Number of iterations d. Essentially so that I understand well how much we are optimizing over vanilla K-Means. Otknm where n is the number of data points k is the number of clusters and t is the number of iterations m is the dimensionality of the vectors.
Time complexity of counting sort is On k where n is the size of array and k is the maximum element in the array not the number of distinct elements. So when I studied about Mini-batch K-Means to make the algorithm converge faster I wanted to find out what is the Space Time complexity of it. Time Complexity of algorithmcode is not equal to the actual time required to execute a particular code but the number of times a statement executes.
In this article an attempt is made to develop an O. The k-means algorithm is known to have a time complexity of O n2 where n is the input data size. K-means clustering minimizes within-cluster variances but not regular Euclidean distances.
Vassilvitskii How slow is the k-means method. I am try to find k-means time complexityI red Arthur and Vassilvitskiis k-means. Number of iterations can be just a big factor in your complexity.
Add a comment. The advantages of careful seeding paper. Therefore the time complexity is O Ikmn.
K-means segmentation is linear in the number of data objects thus increasing execution time. For the second part I would also say no you cant add the complexity like this. Number of attributes My gut feeling is that in your case number of iterations and number of attributes is assumed to be constant.
For large data-sets where k. Lets say that your k-means is refining your data. For example if we have the array A text1 2 3 3 3 4 5 8 8 Lets say that for our array n 9 because we have 9 elements and k 8 because our biggest element is 8.
In this answer note that iused in the k-means objective formula and iused in the analysis of the time complexity of k-means that is the number of iterations needed until convergence are different. An Efficient K-Means Clustering Algorithm for Reduc-ing Time Complexity using Uniform Distribution Data Points D. However - construction requires many dimensions does not preclude an upper bound 58 O n d.
Ganga lakshmi 11 proposed a method for making the K-Means algorithm more valuable and profes-sional. Ordinates are obtained by means of computing the average of each of the co-ordinates of the points of samples assigned to the clusters. It doesnt take more time in classifying similar characteristics in data like hierarchical algorithms.
This quadratic complexity debars the algorithm from being effectively used in large applications. They said O logK-competitive but dont understand it. This quadratic complexity debars the algorithm from being effectively used in large applications.
Looking at these notes time complexity of Lloyds algorithm for k-means clustering is given as. Number of points K. So as to get better clustering with abridged complexity.
We can prove this by using time command. For a K-Means model time complexity mentioned above will be multiplied by iteration amount after which complexity can be expressed as.

Kmeans Clustering By Gradual Data Transformation Mikko Malinen

Pdf A Linear Time Complexity K Means Algorithm Using Cluster Shifting
Privpapers Ssrn Com

Pdf Comparative Analysis Of K Means And Fuzzy C Means Algorithms Semantic Scholar
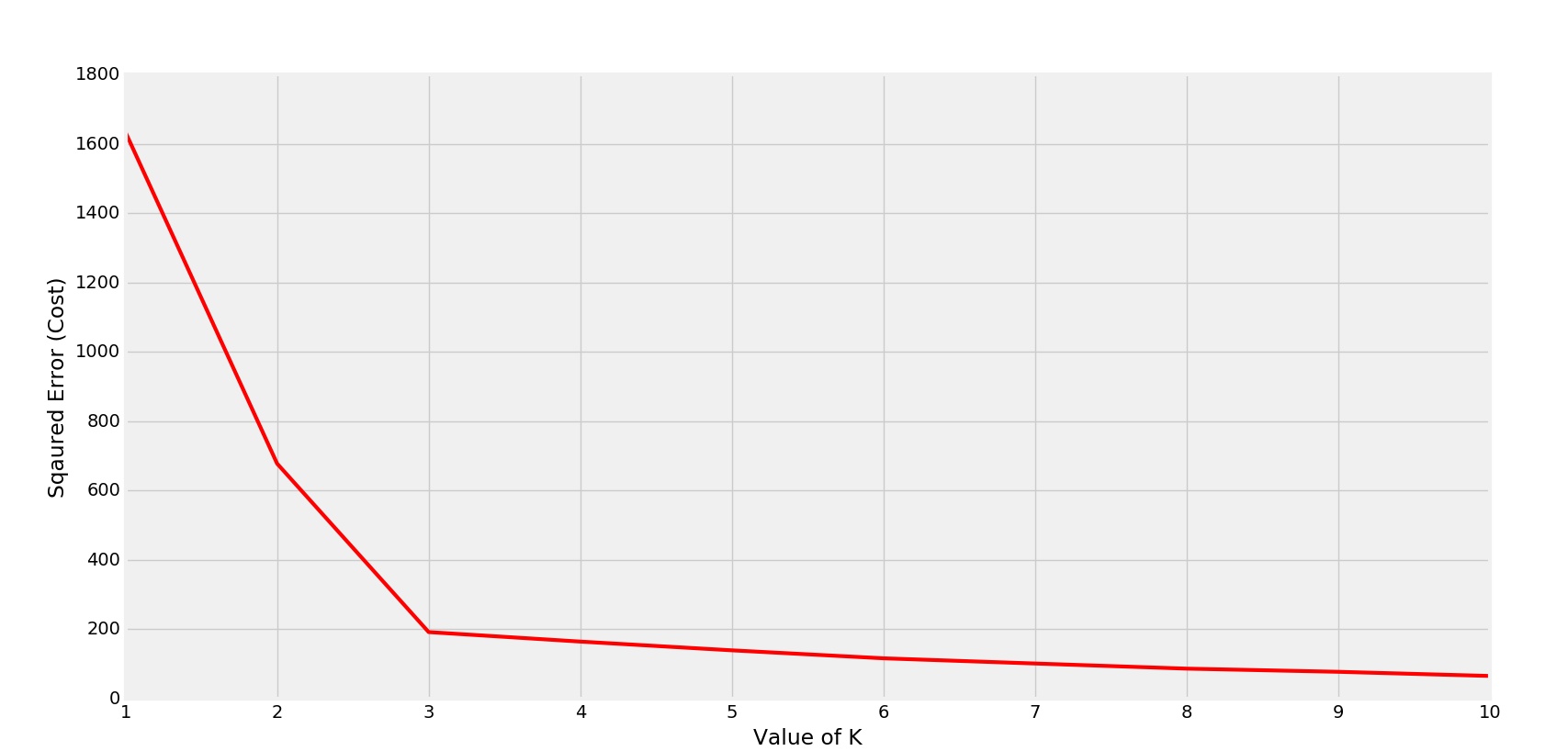
Ml Determine The Optimal Value Of K In K Means Clustering Geeksforgeeks

Evaluation Of Time Complexity Based On Triangle Height For K Means Clustering Semantic Scholar

Time Complexity Comparison Between K Means Fcm Download Scientific Diagram
Time Complexity Comparison Among K Means H Ec 2 S And Ih Ec 2 S Download Scientific Diagram

Comparison Of Time Complexity Download Table

Complexity Measure Of The K Means And The Modified K Means With 100 Download Scientific Diagram

K Means

A Linear Time Complexity K Means Algorithm Using Cluster Shifting Semantic Scholar

Pdf Time Complexity Of K Means And K Medians Clustering Algorithms In Outliers Detection Semantic Scholar

Pdf Comparative Analysis Of K Means And Fuzzy C Means Algorithms Semantic Scholar
Thesai Org

A Linear Time Complexity K Means Algorithm Using Cluster Shifting Semantic Scholar

Comparison Of Time Complexity Of Different Clustering Algorithms Download Scientific Diagram
Table Ii From Comparative Analysis Of K Means With Other Clustering Algorithms To Improve Search Result Semantic Scholar
![]()
Total Time Complexity Measured Processing Time Plus Estimated Data Download Scientific Diagram




Post a Comment
Post a Comment